library(tidyverse)
library(janitor)
library(tm)
library(wordcloud)C1. Taller práctico
Para la actividad de hoy vamos a trabajar con el libro de Harry Potter 3 - El prisionero de Azkaban de J.K Rowling1

Los paquetes
Sobre los paquetes
Tidyverse es un conjunto de paquetes de R. Se utiliza para analizar datos y está compuesto por paquetes que comparten una filosofía de diseño, gramática y estructura. Más información acá
esquisse es un paquete que permite generar graficos con ggplot a partir de una manera interactiva utilizando drag and drop. Más información acá
janitor contiene funciones para limpiar y examinar datos. Más información acá
Cargamos el libro
# Cargamos los datos
hp3 <- readLines("data/hp3.txt")
# Lo convertimos en un solo vector
libro <- paste(hp3, collapse = " ")
# Vemos los primeros caracteres
print(substr(libro, 1, 500)) [1] "J.K. Rowling Harry Potter y el prisionero de Azkaban Por la cicatriz que lleva en la frente, sabemos que Harry Potter no es un niño como los demás, sino el héroe que venció a lord Voldemort, el mago más temible y maligno de todos los tiempos y culpable de la muerte de los padres de Harry. Desde entonces, Harry no tiene más remedio que vivir con sus pesados tíos y su insoportable primo Dudley, todos ellos muggles, o sea, personas no magas, que desprecian a su sobrino debido a sus poderes. Igual"¿Cuantos caracteres tiene el libro?
# ¿Cuantos caracteres tiene el libro?
nchar(libro)[1] 644726¿Cuantas oraciones tiene el libro?
oraciones <- unlist(str_split(libro, "(?<=[.!?])\\s+"))
length(oraciones)[1] 10603Frecuencia de palabras más utilizadas
Limpiamos el texto
gsub() es una función en R que se usa para buscar y reemplazar texto dentro de cadenas de caracteres.
La sintaxis es:
gsub("patrón_a_buscar", "nuevo_texto", texto)A través de esta función vamos a limpiar el texto del libro para mejorar el conteo de las palabrbas
# Convertimos a minusculas
libro_limpio <- tolower(libro)
# Eliminamos las puntuaciones
libro_limpio <- gsub("[[:punct:]]", "", libro_limpio)
# Eliminamos los números
libro_limpio <- gsub("[[:digit:]]", "", libro_limpio)
# Eliminamos espacios múltiples
libro_limpio <- gsub("\\s+", " ", libro_limpio)
libro_limpio <- gsub("[^\x20-\x7E]", "", libro_limpio) # Elimina caracteres no imprimiblesDividimos las palabras
# Divido las palabras:
palabras <- unlist(strsplit(libro_limpio, "\\s+")) Eliminamos las stopwords
Las stopwords (o palabras vacías) son palabras muy comunes en un idioma que suelen tener poco valor en análisis de texto porque no aportan significado relevante. Ejemplos en español incluyen:
🔹 Preposiciones: “de”, “a”, “con”, “por”, “para” 🔹 Artículos: “el”, “la”, “los”, “las” 🔹 Conjunciones: “y”, “o”, “pero”, “aunque” 🔹 Pronombres: “yo”, “tú”, “él”, “ella”, “nosotros” 🔹 Verbos auxiliares: “ser”, “estar”, “haber”
stopwords_es <- stopwords("es")
# Vector sin los stopwords
palabras_filtradas <- palabras[!palabras %in% stopwords_es] Contamos
frecuencia <- table(palabras_filtradas)
# Ordenamos por la frecuencia
frecuencia <- sort(frecuencia, decreasing = TRUE)
# Top 20 palabras
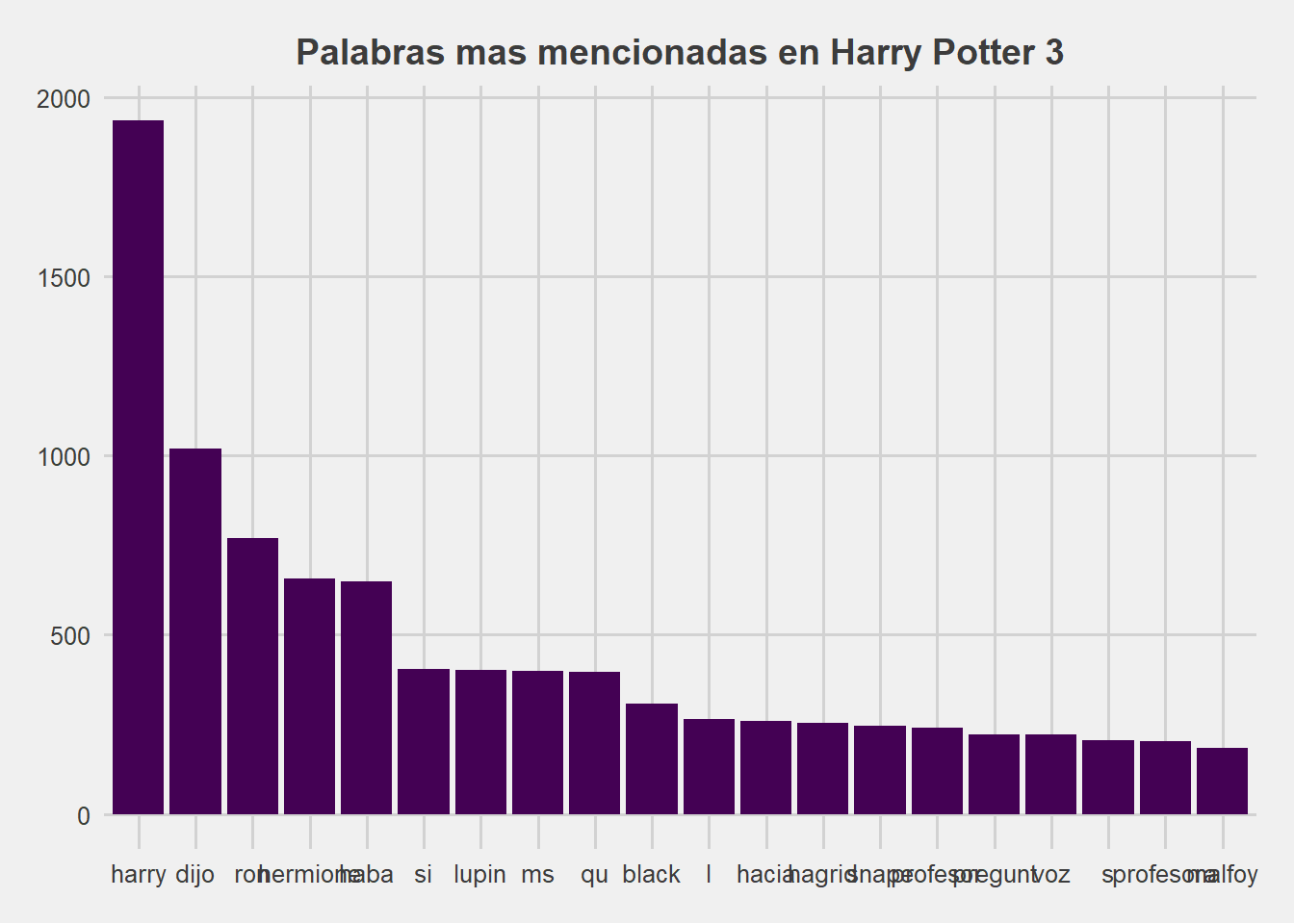
head(frecuencia, 20)palabras_filtradas
harry dijo ron hermione haba si lupin ms
1935 1020 769 656 649 404 401 400
qu black l hacia hagrid snape profesor pregunt
397 307 264 260 253 245 242 223
voz s profesora malfoy
222 206 203 185 Graficamos
- Convertimos nuestras frecuencias en una tabla
df_frec <- as.data.frame(frecuencia)
colnames(df_frec) <- c("Palabra", "Frecuencia")
head(df_frec) Palabra Frecuencia
1 harry 1935
2 dijo 1020
3 ron 769
4 hermione 656
5 haba 649
6 si 404Me quedo con las 20 palabras más mencionadas y grafico utilizando esquisser
df_grafico <- df_frec |>
head(20)esquisse::esquisser(df_grafico)Lo diseñamos a gusto y luego guardamos el código
# Grafico final
ggplot(df_grafico) +
aes(x = Palabra, y = Frecuencia) +
geom_col(fill = "#440154") +
labs(
x = "Palabras",
y = "Cantidad",
title = "Palabras mas mencionadas en Harry Potter 3"
) +
ggthemes::theme_fivethirtyeight() +
theme(
legend.justification = "top",
plot.title = element_text(size = 14L,
face = "bold",
hjust = 0.5)
)
Nube de palabras
También podemos realizar una nube de palabras:
wordcloud(names(frecuencia), frecuencia, max.words = 100, colors = brewer.pal(8, "Dark2"))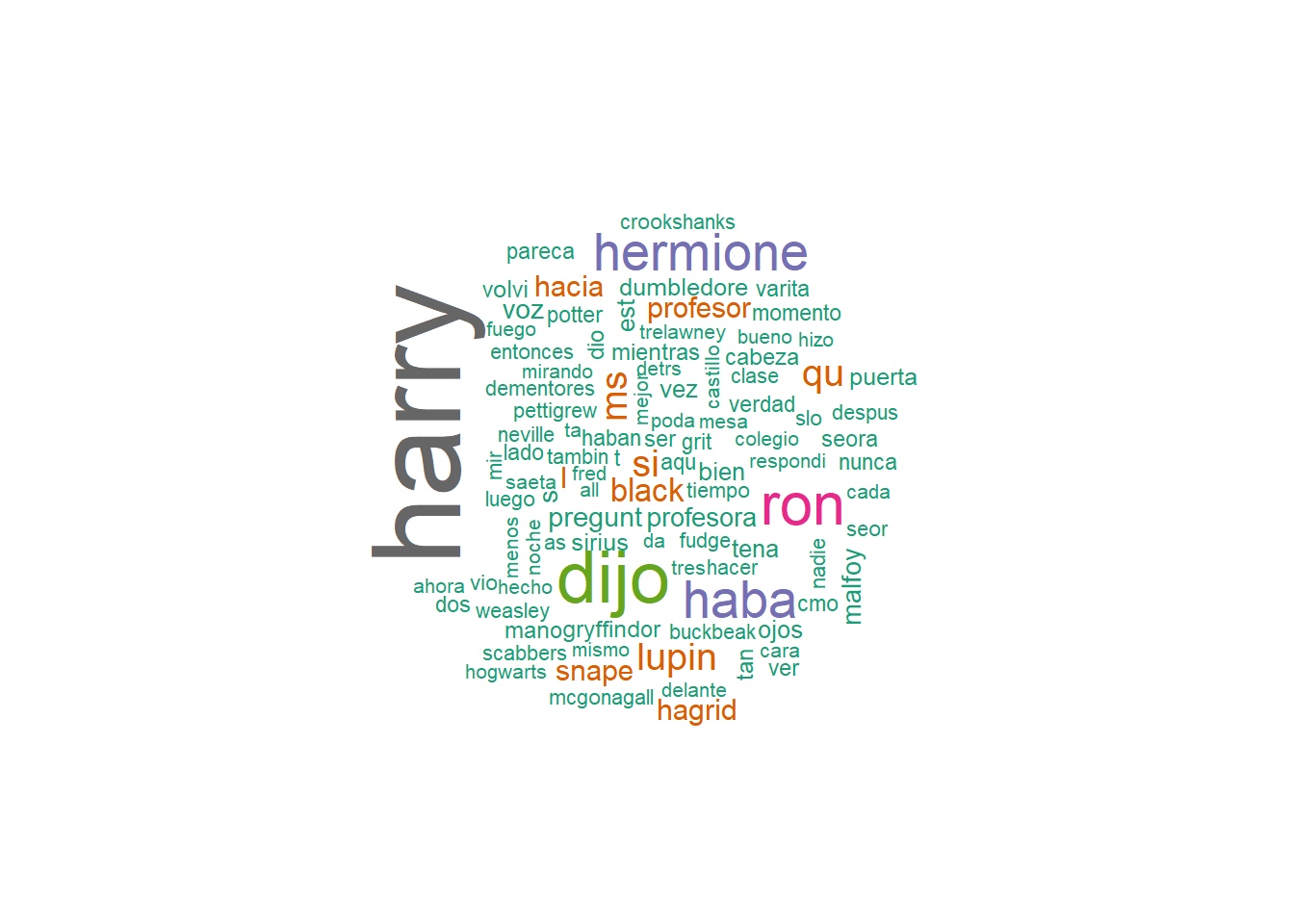
J. K. Rowling . (1999). Harry Potter y el prisionero de Azkaban. Reino Unido: Bloomsbury.↩︎